The first blog dealt
with longitudinal population surveillance data and explained how we accurately
and comprehensively represent a record of everyone who is under surveillance
over time. In this blog we explain how we process the data to produce the consolidated longitudinal population dataset. The preparation of the dataset happens in two broad phases. During
a Data Managers’ Workshop held in 2018 (comprising the three nodes that
currently make up SAPRIN), an agreement was reached that each SAPRIN node must populate
the standard SAPRIN database structure with data from their operational longitudinal
database.
The nodes are expected to annually submit both copies of the databases to the SAPRIN Management hub. The data received from the nodes is then hosted on the Microsoft Azure platform. Microsoft Azure is Microsoft's public cloud computing platform. Microsoft Azure provides a range of cloud services, including compute, analytics, storage and networking. Figure 1 illustrates the high-level architecture of the dataset production process.
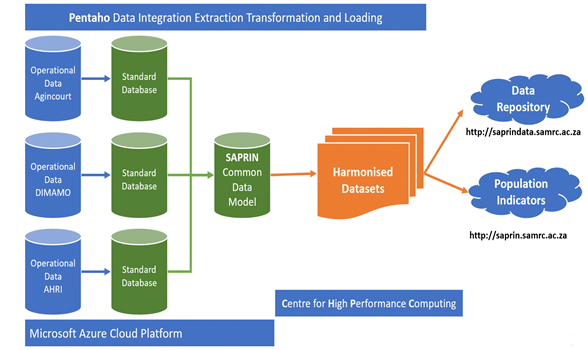


The nodes are expected to annually submit both copies of the databases to the SAPRIN Management hub. The data received from the nodes is then hosted on the Microsoft Azure platform. Microsoft Azure is Microsoft's public cloud computing platform. Microsoft Azure provides a range of cloud services, including compute, analytics, storage and networking. Figure 1 illustrates the high-level architecture of the dataset production process.
Figure 1: High Level Architecture
The first step in the data preparation
process is Quality Assurance. The SAPRIN Management hub team assesses the data
submitted to ensure it is in the correct format and falls within expected value
ranges. Other potential issues to check include: missing data, incorrect data
types, unexpected duplicate or orphan records. The SAPRIN Management hub assesses
this conversion by running both original operational database and the SAPRIN database
created from the operational database through the iSHARE data quality
assessment and indicator process. The data quality checking process is
developed using Pentaho Data Integration.
The principle of the data quality
checks is that if the data conversion conducted by the nodes is complete and
accurate, there should be little or no difference in the data quality and demographic
indicators between the base and SAPRIN versions of the nodal data. Table 1 shows
an example of selected demographic indicators for the period 2000-2017, after
running both original operational database and the SAPRIN database through the
iSHARE data quality assessment and indicator process.

Table 1: Demographic Indicators
If the data submitted by the nodes meets the criteria for
inclusion into the consolidated dataset the data moves to the second step of
the data production process. However, if the data fail the inclusion checks, this
could then lead to another iteration of data submission and quality control
checks until SAPRIN Management hub is satisfied that they have high quality
data.
The next phase of the dataset preparation process is to use the verified
data to produce the consolidated longitudinal population dataset. This phase of
the dataset production follows a standard process to ensure the consistency and
quality of the datasets hosted on the SAPRIN Data Repository. This phase of the
dataset production happens on the Centre for High Performance Computing (CHPC)
platform. SAPRIN has signed a Memorandum of Agreement (MOA) with the CHPC to
formalise the use of the CHPC platform. CHPC has provided SAPRIN three compute nodes on the CHPC's Lengau cluster to process the consolidated
data. Each compute node has
24 cores and 128GB of RAM. The job to produce the dataset is written using
Pentaho Data Integration .
Figure 2 shows the master PDI job that is used
to produce the dataset. The data that is stored in the nodal operational
databases is episodic. In order to convert this episodic data into data that
will be easily used by researchers this episodic data from the nodes is first decomposed
to day level, so that for every individual under surveillance we have a record
for that individual at day level (DP04 Day Extraction). Decomposing the data to
day level allows us to combine with other data streams to answer specific
questions such as over the life of a child at what point was the child
co-resident with the mother and/or father?
Figure 2: Dataset Production Job using
Pentaho Data Integration
The data is then collapsed back (if none of the dimensional
attributes change over the specific period). The job DP08 Produce Episodes produces the final detailed STATA 11 and csv datasets. SAPRIN uses Nesstar Publisher for editing to prepare the DDI compliant
metadata that documents each dataset on the repository. In order to have consistency in the datasets published
on the SAPRIN data portal SAPRIN uses a standard metadata template for the
SAPRIN Data Repository Datasets. The SAPRIN data repository uses Public use data files access
level- which means the user must be logged in and registered on the SAPRIN data
portal before they are able to download the data.
The registered user is
required to agree to the terms of use of the dataset. Some of the conditions of
use of the dataset are that: (1) The data and other materials provided by
SAPRIN will not be redistributed or sold to other individuals, institutions, or
organizations without the written agreement of SAPRIN; (2) Any books, articles, conference papers,
theses, dissertations, reports, or other publications that employ data obtained
from SAPRIN will cite the source of data in accordance with the Citation
Requirement provided with each dataset.Once the user has successfully downloaded the dataset, SAPRIN keeps
a record of who has downloaded the dataset. SAPRIN is registered with Dara through
the GESIS–Leibniz Institute for the Social Sciences
and has been allocated the 10.23667 doi
prefix. All SAPRIN datasets are registered with a unique doi that must be
included when the dataset is cited.
Comments
Post a Comment